
抖音的上热门的方法类似于威尔逊得分排序算法,但是远远又比威尔逊得分排序算法更复杂。
大概就是:
机器审核+人工双重审核。
当一个视频初期上传,平台会给你一个初始流量,如果初始流量之后,根据点赞率,评论率,转发率,进行判断:该视频是受欢迎还是不受欢迎,如果第一轮评判为受欢迎的,那么他会进行二次传播。
当第二次得到了最优反馈,那么就会给与推荐你更大的流量。
相反,在第一波或者第N波,反应不好,就不再推荐,没有了平台的推荐,你的视频想火的概率微乎其微,因为没有更多的流量能看见你。
你的视频火的第一步是被别人看见,第一步就把路给走死了,后续也只能依靠朋友星星点点的赞。
其实,不难看出这个抖音推荐机制算法背后思维逻辑:流量池,叠加推荐,热度加权及用户心理追求。
下面还是来了解一下威尔逊得分(Wilson Score)排序算法吧!
威尔逊得分排序算法,Wilson Score,用于质量排序,数据含有好评和差评,综合考虑评论数与好评率,得分越高,质量越高。
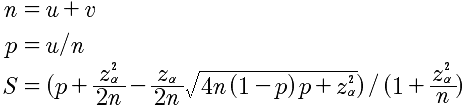

u表示正例数(好评),v表示负例数(差评),n表示实例总数(评论总数),p表示好评率,z是正态分布的分位数(参数),S表示最终的威尔逊得分。z一般取值2即可,即95%的置信度。
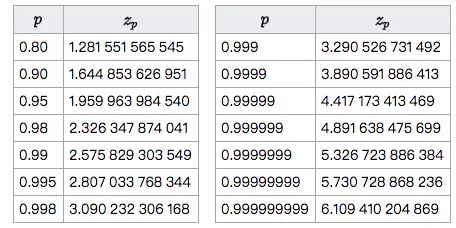
正太分布的分位数表:
算法性质:
- 性质:得分S的范围是[0,1),效果:已经归一化,适合排序
- 性质:当正例数u为0时,p为0,得分S为0;效果:没有好评,分数最低;
- 性质:当负例数v为0时,p为1,退化为1/(1 + z^2 / n),得分S永远小于1;效果:分数具有永久可比性;
- 性质:当p不变时,n越大,分子减少速度小于分母减少速度,得分S越多,反之亦然;效果:好评率p相同,实例总数n越多,得分S越多;
- 性质:当n趋于无穷大时,退化为p,得分S由p决定;效果:当评论总数n越多时,好评率p带给得分S的提升越明显;
- 性质:当分位数z越大时,总数n越重要,好评率p越不重要,反之亦然;效果:z越大,评论总数n越重要,区分度低;z越小,好评率p越重要;
def wilson_score(pos, total, p_z=2.): """
威尔逊得分计算函数
参考:https://en.wikipedia.org/wiki/Binomial_proportion_confidence_interval
:param pos: 正例数
:param total: 总数
:param p_z: 正太分布的分位数
:return: 威尔逊得分
""" pos_rat = pos * 1. / total * 1. # 正例比率 score = (pos_rat + (np.square(p_z) / (2. * total))
- ((p_z / (2. * total)) * np.sqrt(4. * total * (1. - pos_rat) * pos_rat + np.square(p_z)))) /
(1. + np.square(p_z) / total) return score
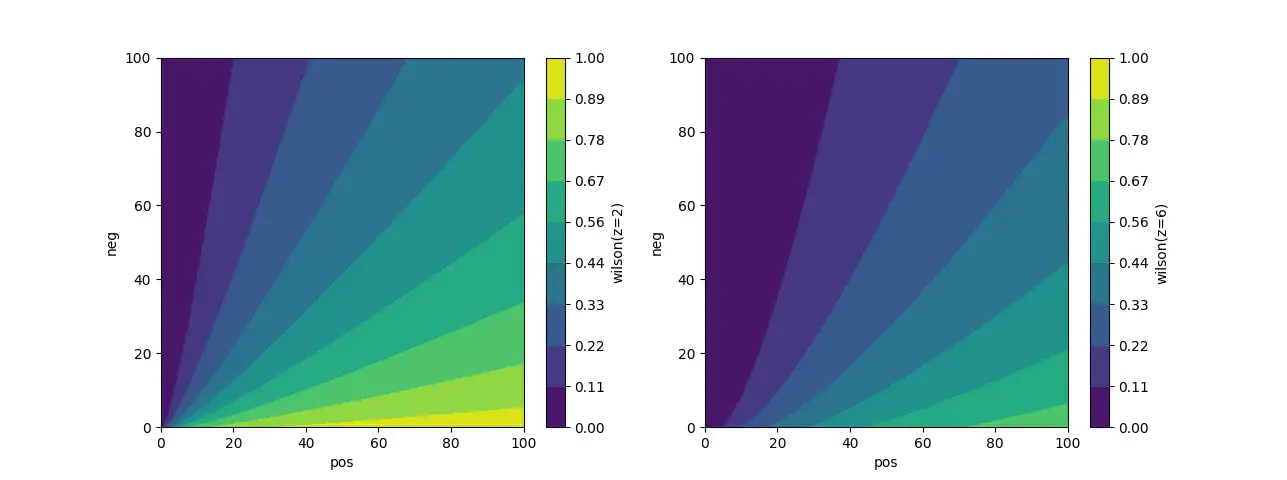
PS:关于z参数,即正太分位数。正太分位数影响wilson得分的分布,z参数取值依据就是样本数的量级。举个例子:同样是100个样本,90个好评,z取值2或6,分数差别很大,体系所容纳(或区分)的样本数也相差较大(同样是0.82分和90%好评率,z=2需要100个样本,z=6需要1000个样本),一般而言,样本数的量级越大,z的取值大。
print 'score: %s' % wilson_score(90, 90 + 10, p_z=2.) print 'score: %s' % wilson_score(90, 90 + 10, p_z=6.) print 'score: %s' % wilson_score(900, 900 + 100, p_z=6.) # 取值2-100:score: 0.823802352689 # 取值6-100:score: 0.606942322627 # 取值6-1000:score: 0.828475631056
威尔逊得分算法的分布图
实例:假设医生A有100个评价,1个差评99个好评。医生B有2个评价,都是好评,那哪个应该排前面?
在z=2时,即95%的置信度,医生A的得分是0.9440,医生B的得分是0.3333,医生A排在前面。
示例:喜剧视频在10次观看中,6次被喜欢,4次不被喜欢;运动类视频在1000次观看中,550次被喜欢,450次不被喜欢
问题:喜剧类视频和运动类视频哪个更受欢迎?
第一种得分方法:得分 = 赞成票 – 反对票 ;很明显,方法一表示运动类视频更受欢迎
第二种得分方法:得分 = 赞成量/总量;很明显,方法二表示喜剧类视频更受欢迎
当样本总量都很大时,其实方法二比较正确,用相对量点赞率作为评分标准,但当总量很小时,比如2次观看中,2次都被喜欢,点赞率岂不是100%,但是因为总量太少不足以说明其可信度。
因此我们可以采用威尔逊置信区间法,有如下设定:
1.视频每次被观看都是独立事件;
2.视频的反馈只有两种:被喜欢和不被喜欢;
3.视频的观看总量为n,其中有k次被喜欢,喜欢的比例p等于k/n.
不难看出,这是一种统计分布,即二项分布:假设在n次独立的实验中,每次试验成功的概率为p,所有成功次数K就是服从参数n和p的二项随机变量。
一般而言,p越大,就代表这类视频的好评比例越高,越应该排在前面。但是,p的可信性,取决于有多少次观看总量,如果样本太小,p就不太可信。就好比一个实验只做一次成功了就说这个实验完美了,也许这次的成功是碰巧因素,我们需要不断地重复做这个实验检验其成功地可信度。我们知道p是二项分布中某个事件的发生概率,可以计算出p的置信区间。
【注意:在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度,其给出的是被测量参数的测量值的可信程度,即前面所要求的“一个概率。】
举个例子:喜剧类视频的点赞率是60%,但是这个概率不可信,根据统计学,可以说有95%(这里是置信水平0.05)把握,其点赞率在55%到65%之间,则其置信区间就是[55%,65%]. 根据样本量对置信区间的影响,当置信水平()固定的时候,样本量越大,置信区间越窄。(另外补充:当样本量不变时,置信水平越高,置信区间越大)。
置信区间和样本总量这一关系,就可以对概率p可信度进行修正,弥补样本量国过小和样本总量差异太大的影响。
当样本总量很小时,说明概率p 不一定可信,需要进行修正,其置信区间比较宽,下限值会比较小;
当样本量比较大时,说明比较可信,不需要较大的修正,其置信区间比较窄,下限值会比较大;
接下来,对不同类型的视频进行排名算法比较清晰了:
第一步:计算每类视频的点赞率;
第二步:计算每个点赞率的置信区间;
第三步:计算置信区间的下限值(wilson-s,进行排名。这个下限值越大,排名越高。
以下是置信区间上下限的界限:下限值最小为0,上限值最大为1
1927年,美国数学家 Edwin Bidwell Wilson提出了一个修正公式,被称为”威尔逊区间”,很好地解决了小样本的准确性问题。
注意:公式中的在上面的公式中,表示样本的”赞成票比例”,n表示样本的大小,表示对应某个置信水平的z统计量,这是一个常数,可以通过查表或统计软件包得到。一般情况下,在95%的置信水平下,z统计量的值为1.96。
不难看出威尔逊置信区间的均值:(上限+下限)/2 :
可以看到,当n的值足够大时,这个下限值会趋向。如果n非常小,这个下限值会大大小于。实际上,起到了降低”赞成票比例”的作用,使得该类视频的得分变小、排名下降。实际示例中也的确如此。
这种排序算法可以消除样本数量差异太大的影响,可以适用于寻找用户兴趣爱好排序问题,进一步进行个性化方向推荐。
几种语言的实现示例。
Java实现
package com.lzhpo.wsdemo1.test1; /**
* 威尔逊得分(Wilson Score)排序算法
*
* @author lzhpo
*/ public class WilsonScoreDemo1 { /**
* 计算威尔逊得分
* <p>
* zP一般取值2即可,即95%的置信度。
* </p>
*
* @param u 好评数
* @param n 评论总数
* @param zP 正态分布的分位数
* @return s 威尔逊得分
*/ public static double wilsonScore(double u, double n, double zP) { // 好评率 double p = u / n;
System.out.println("好评率为:" + p); // 威尔逊得分 double s = (p + (Math.pow(zP, 2) / (2. * n)) - ((zP / (2. * n)) * Math.sqrt(4. * n * (1. - p) * p + Math.pow(zP, 2)))) / (1. + Math.pow(zP, 2) / n);
System.out.println("威尔逊得分为:" + s); return s;
} public static void main(String[] args) { // 计算结果:0.46844027984510983 System.out.println(wilsonScore(500, 1000, 2));
}
}
Python实现
import numpy as np def wilson_score(u, n, zP=2.): """
威尔逊得分(Wilson Score)排序算法 => 计算威尔逊得分
:param u: 好评数
:param n: 评论总数
:param zP: 正太分布的分位数(zP一般取值2即可,即95%的置信度)
:return: 威尔逊得分
""" pos_rat = u * 1. / n * 1. score = (pos_rat + (np.square(zP) / (2. * n))
- ((zP / (2. * n)) * np.sqrt(4. * n * (1. - pos_rat) * pos_rat + np.square(zP)))) / (1. + np.square(zP) / n) return score # 计算结果:0.46844027984510983 print(wilson_score(500, 1000, 2))
Go实现
package main import ( "fmt" "math" ) // 威尔逊得分(Wilson Score)排序算法 func main() { // 计算结果:0.46844027984510983 wilsonScore(500, 1000, 2)
} // 计算威尔逊得分 // u:好评数 zP:正态分布的分位数(一般取值2即可,即95%的置信度) s:威尔逊得分 func wilsonScore(u float64, n float64, zP float64) float64 {
p := u / n println()
fmt.Println("好评率为:", p)
s := (p + (math.Pow(zP, 2) / (2. * n)) - ((zP / (2. * n)) * math.Sqrt(4.*n*(1.-p)*p+math.Pow(zP, 2)))) / (1. + math.Pow(zP, 2)/n)
fmt.Println("威尔逊得分为:", s) return s
}
PHP实现
<?php function wilsonScore_2($n, $total, $z){
$p = $n/$total;
$a_1 = ((1 / (2 * $n)) * ( pow($z,2)));
$b_1 = $z * sqrt(($p * (1 - $p) / $n) + ( pow($z,2) / (4 * (pow($n,2)))));
$c_1 = 1 + ((1 / $n) * ( pow($z,2)));
$numerator = $p + $a_1 - $b_1;
$res = $numerator/$c_1; return $res;
} echo wilsonScore_2( 290,300, 2);
该文章投稿作者:梦见自己住在工棚里,如若转载,请注明来自鱼鳞桐程网:https://www.yulintongcheng.com/199519.html